當大型語言模型遇上知識圖譜 優勢互補驅動軟件開發新范式
人工智能領域的兩大核心技術——大型語言模型(LLM)和知識圖譜(KG)——正以前所未有的方式交匯融合。這一融合不僅是技術發展的自然趨勢,更是解決各自局限、釋放協同潛力的關鍵路徑。在軟件開發這一復雜且知識密集的領域,LLM與知識圖譜的優勢互補,正在催生更智能、更可靠、更高效的下一代開發工具與方法論。
一、兩大技術的核心優勢與固有局限
大型語言模型(LLM),如GPT系列、LLaMA等,以其強大的自然語言理解與生成能力著稱。其優勢在于:
1. 泛化與涌現能力:能夠處理未見過的任務指令,通過上下文學習(In-Context Learning)快速適應新場景。
2. 強大的語義理解與生成:在代碼生成、注釋撰寫、需求分析等涉及自然語言的軟件開發環節表現出色。
3. 交互的流暢性:提供類人的、流暢的對話交互體驗,極大降低了開發工具的使用門檻。
LLM也存在顯著局限:其知識可能“過時”或“幻覺”(產生事實性錯誤),推理過程如同“黑箱”,缺乏可解釋性,且難以保證復雜邏輯的精確性與一致性。
知識圖譜(KG) 則以結構化的方式組織和表示實體、概念及其間關系。其優勢在于:
1. 精確的結構化知識:以三元組(頭實體,關系,尾實體)等形式存儲明確、可驗證的事實性知識。
2. 可解釋的推理路徑:基于圖結構的查詢和推理(如路徑查詢、規則推理)過程透明、邏輯清晰。
3. 動態可更新性:知識可以模塊化地增、刪、改,確保知識庫的時效性和準確性。
其局限則在于構建與維護成本高,對非結構化文本的理解和獲取依賴額外技術,且靈活性和自然交互能力不足。
二、優勢互補:構建“大腦”與“知識庫”的共生系統
將LLM與知識圖譜結合,實質上是將LLM強大的感知、生成和泛化能力,與知識圖譜精確、結構化、可推理的知識底座相結合,形成“系統1(直覺、快速)”與“系統2(慢速、邏輯)”思維模式的協同。在軟件開發中,這種互補體現為:
1. 知識增強的代碼生成與理解:
- 場景:開發者輸入需求描述(如“創建一個用戶登錄的REST API端點”)。
- 融合應用:LLM首先理解自然語言需求。知識圖譜(包含項目特定的API規范、架構模式、領域術語、歷史代碼模式等)則作為外部知識源被LLM檢索或查詢,確保生成的代碼符合項目規范、使用了正確的庫版本和設計模式,并避免了已知的安全漏洞。這極大地提升了生成代碼的準確性、一致性和安全性。
2. 智能化的軟件知識管理與問答:
- 場景:新成員加入項目,或開發者遇到復雜模塊時尋求理解。
- 融合應用:知識圖譜構建起項目的“知識地圖”(包括代碼依賴、類/函數關系、文檔鏈接、需求追蹤等)。LLM作為自然語言前端,允許開發者用日常語言提問(如“這個支付模塊修改后會影響哪些下游服務?”)。LLM將問題解析并轉化為對知識圖譜的查詢,圖譜提供精確的關聯路徑和實體信息,再由LLM組織成流暢、易懂的答案。這實現了對大型代碼庫的深度、可解釋的探索。
3. 需求工程與架構設計的協同輔助:
- 場景:從模糊的需求文檔到清晰的系統設計。
- 融合應用:LLM可以輔助解析用戶故事、提取功能性需求和非功能性需求。這些提取出的實體(如“用戶”、“訂單”、“支付網關”)和約束(如“響應時間<100ms”)被結構化地存入知識圖譜。基于圖譜中積累的架構決策記錄和設計模式,系統可以輔助推薦或驗證架構方案,LLM則生成設計文檔的初稿。這使需求到設計的鏈路更加連貫、可追溯。
4. 軟件測試與漏洞分析的強化:
- 場景:生成測試用例或進行靜態安全分析。
- 融合應用:知識圖譜存儲已知的漏洞模式、代碼壞味道、測試用例模板等。LLM分析待測代碼后,從圖譜中檢索相關模式,生成更具針對性、覆蓋關鍵風險的測試代碼或安全警告,并提供基于圖譜的修復建議參考。
三、融合路徑與關鍵技術
實現有效融合主要依賴以下技術路徑:
- 檢索增強生成(RAG):這是當前最主流的結合方式。在LLM處理輸入(如問題、指令)時,先從知識圖譜(或通過圖譜索引的文本)中檢索最相關的結構化信息,作為上下文提供給LLM,從而引導其生成更準確、可靠的輸出。
- 圖增強的LLM預訓練/微調:在LLM的訓練數據中引入知識圖譜的三元組信息,或在特定領域(如某個軟件棧)上使用圖譜數據對LLM進行微調,使模型內部隱式地編碼更多結構化知識。
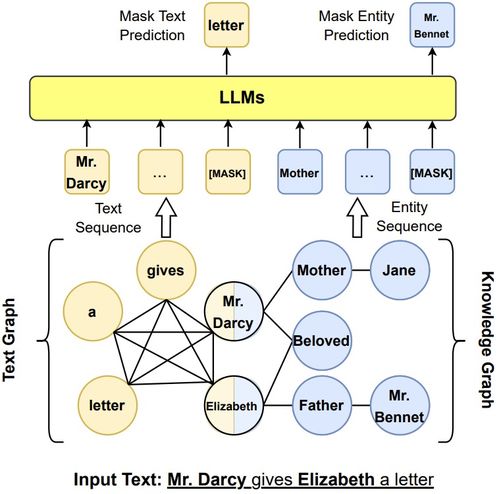
- LLM賦能的圖譜構建與維護:利用LLM強大的文本理解能力,自動化或半自動化地從源代碼、文檔、提交日志等非結構化文本中抽取實體和關系,以構建或更新軟件知識圖譜,解決圖譜構建的瓶頸問題。
- 代理(Agent)框架中的協同:在AI代理框架中,LLM作為“規劃中心”和“交互界面”,知識圖譜則作為其可信的“記憶體”和“事實核查庫”。代理可以執行“從圖譜查詢依賴關系”、“將新決策寫入圖譜”等工具調用,完成復雜的軟件工程任務。
四、挑戰與未來展望
盡管前景廣闊,融合之路仍面臨挑戰:如何實現大規模、高質量軟件知識圖譜的低成本構建與同步更新;如何設計高效的圖譜-LLM交互協議以平衡精度與速度;如何評估這類混合系統的整體效能等。
LLM與知識圖譜的深度融合,將推動軟件開發向“知識驅動、AI增強”的新范式演進。開發者將更像是一位“總監”,指揮著一個由LLM(處理創意和模糊任務)和知識圖譜(確保精確和一致)組成的智能助手團隊。軟件系統本身也將更可能內嵌這種混合智能,實現更高程度的自解釋、自演進和自適應維護。這場兩大技術的“聯姻”,正為軟件工程的自動化與智能化開啟一扇全新的大門。
如若轉載,請注明出處:http://m.jq245.cn/product/57.html
更新時間:2026-01-07 13:47:11